Real-Time Stock Market Data Analytics Pipeline on AWS with Terraform
Modern businesses succeed when they can turn fresh data into action. Markets move quickly, and the sooner you can detect a pattern, the faster you can respond. This project demonstrates a lean, production-friendly approach to real-time analytics on AWS: ingest stock ticks, process them immediately, archive raw events for historical analysis, compute trends, and make the results queryable with SQL. Everything is defined as code with Terraform modules, so it is easy to deploy, reason about, and evolve.
This post explains how the project is built, how each component works and interacts with others, why the architecture is cost efficient, and how organizations can benefit from it.
What We Built
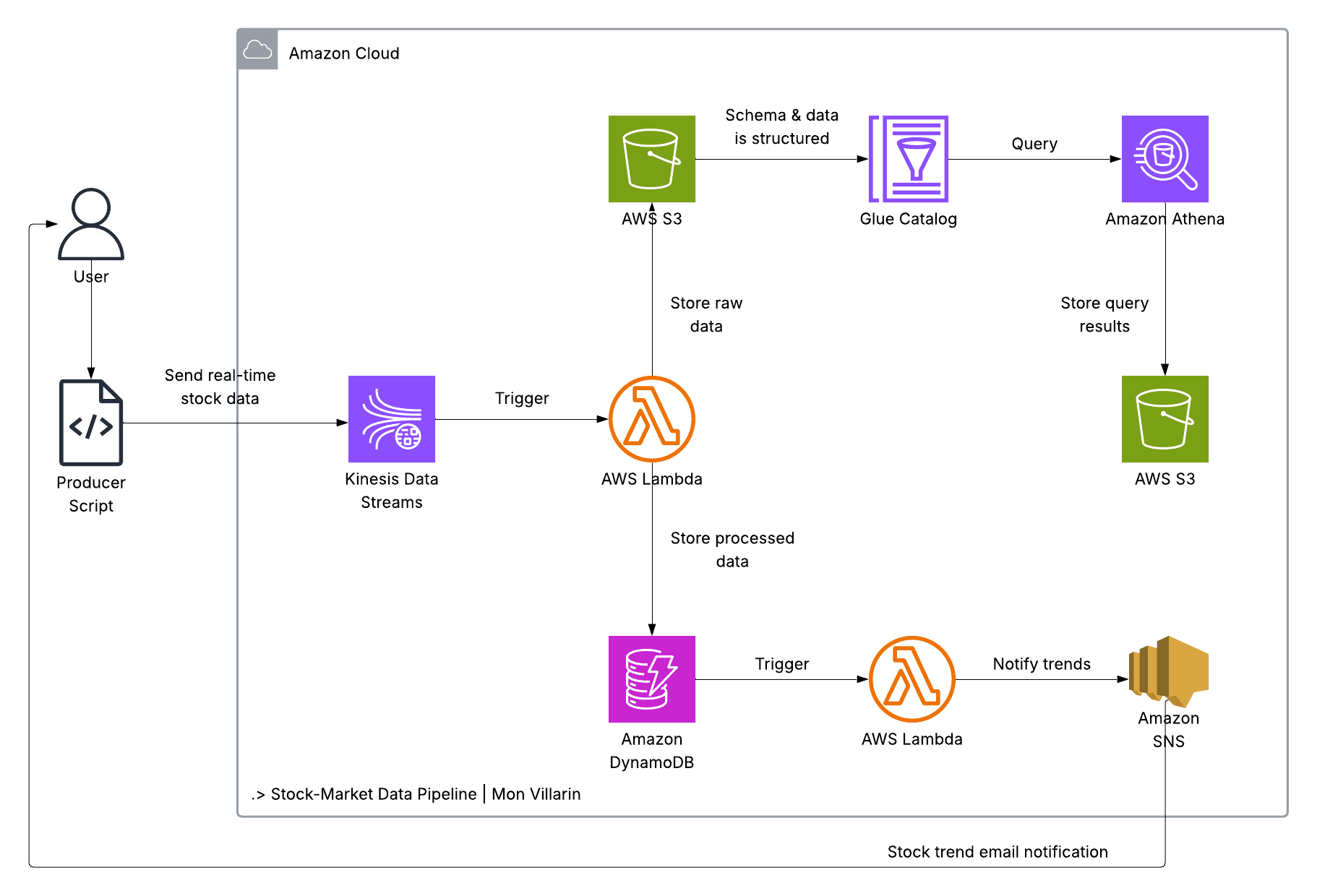
At a high level, the pipeline consists of:
A lightweight producer script that writes stock ticks to Amazon Kinesis Data Streams.
A Lambda consumer that validates and transforms records, saves curated data in DynamoDB, and archives raw JSON to Amazon S3.
A trend-analysis Lambda that listens to DynamoDB Streams, computes simple moving averages (SMAs), and publishes alerts via Amazon SNS.
An AWS Glue Catalog database and table that make raw data in S3 discoverable and queryable by Amazon Athena.
Small Terraform modules for each AWS component, assembled in a clear, hardcoded root configuration.
The result is an end-to-end, serverless analytics stack that scales with traffic, keeps costs tied to usage, and provides both real-time and historical paths for analysis.
Components and How They Work Together
Ingestion: Amazon Kinesis Data Streams

Data ingestion is handled by Amazon Kinesis Data Streams. Kinesis provides a durable, scalable, ordered log for events. In this project we use a single shard, which supports up to 1,000 records per second or 1 MB per second of writes. If your throughput grows, you can scale horizontally by adding shards.
A small Python program, producer_data_function.py, fetches data for a symbol (AAPL by default) using the yfinance library. When real market data is unavailable, it generates realistic mock data so the pipeline can be demonstrated offline. The producer publishes a compact JSON document including fields like symbol, open, high, low, price, previous_close, volume, a source flag, and an ISO 8601 timestamp. It sends a new record every 30 seconds.
The producer reads the stream name from an environment variable KINESIS_STREAM_NAME (defaulting to stock-market-stream). That makes it simple to point the producer to different streams without changing code.
Real-Time Processing: Lambda Consumer for Kinesis

The first AWS Lambda function, ConsumerStockData, is connected to the Kinesis stream via an event source mapping. When new records arrive, Kinesis batches them (batch size is configurable, 2 in this example) and invokes the function. The function:
Decodes and validates each JSON payload, ensuring required fields like symbol, price, and timestamp are present and well typed.
Archives the raw event in S3 under a logical, time-based path:
raw/YYYY/MM/DD/HH/.... This provides a natural partitioning scheme for later analytics.Writes a curated item to DynamoDB containing the symbol, timestamp, and price, plus optional attributes such as volume or exchange.
Why write to both S3 and DynamoDB? DynamoDB is optimized for fast key-value and range queries and is perfect for real-time lookups and dashboards. S3 is the long-term system of record and data lake. By archiving every raw record in S3, you can run backfills, ad-hoc analytics, and train ML models using complete history, without touching production tables.
Insights: Trend Analysis with DynamoDB Streams and Lambda

The second Lambda function, StockTrendAnalysis, is triggered by DynamoDB Streams. Whenever the stock-market-data table changes, DynamoDB emits a stream record. The function queries recent items for a symbol (for example the last few minutes), computes short and long simple moving averages (such as SMA-5 and SMA-20), and detects crossovers that may indicate an uptrend or downtrend.
If a signal is detected, the function publishes a message to an Amazon SNS topic named stock-trend-alerts. For ease of testing, the project creates a standard email subscription; you confirm the subscription by clicking a link in an AWS email. In production, you could send alerts to SMS, HTTPS webhooks, Slack, or event buses, all via SNS.
Both Lambda functions use environment variables for configuration. For example, the consumer reads the DynamoDB table name and S3 bucket name from its environment, and the trend function reads the table name and SNS topic ARN. This approach lets you move across environments without code changes.
Archival and Query: S3, Glue Catalog, and Athena

All raw events are archived in S3. The project creates two buckets: one for raw data (stock-market-data-bucket-121485) and another for query results (athena-query-results-121485). Raw data is stored as JSON. An AWS Glue Catalog database and table define the schema over the S3 prefix so Amazon Athena can run SQL queries against the JSON files.
Athena itself is not an infrastructure resource to provision in Terraform (it is a serverless query service). Still, the project fully prepares the environment for Athena by creating the Glue Catalog and a results bucket. You can immediately explore the data from the Athena console using standard SQL and save or share queries as needed.
Access and Security: IAM
Two IAM roles are created using a reusable module. One role is for the Kinesis consumer Lambda; the other is for the trend-analysis Lambda. Managed policies grant access to the required services: DynamoDB, Kinesis (for the consumer), S3, SNS (for trend alerts), and CloudWatch Logs. As you harden the solution, you can replace broad managed policies with narrow, resource-level policies.
Implementation Approach: Terraform Modules

The project is intentionally simple to make the design easy to understand and extend. Each AWS service is represented by a small Terraform module. The root configuration calls those modules and passes explicit values. This makes resource relationships and data flow very clear.
modules/kinesis: Kinesis stream with name, shard count, retention, and encryption settings.modules/lambda_function: Creates a Lambda function and an event source mapping. It supports event sources from Kinesis streams and DynamoDB Streams via a genericevent_source_arnvariable.modules/dynamodb: Creates thestock-market-datatable with on-demand billing, server-side encryption, point-in-time recovery, and a DynamoDB Stream.modules/s3_bucket: Creates S3 buckets with versioning, encryption, public access blocks, and force-destroy on delete so destroys do not fail on non-empty buckets.modules/glue_catalog: Defines a Glue database and table using a JSON SerDe for the archived S3 data.modules/iam_role: Creates IAM roles and attaches managed policies passed as variables.modules/sns: Creates an SNS topic and a subscription (email protocol).
The root main.tf wires these modules together, passing identifiers like ARNs where needed. The Lambda module references local ZIP artifacts for the functions and uses source_code_hash so updates are deployed when the package changes.
Cost Efficiency: Why This Architecture Is Affordable
This design keeps costs tied to usage and eliminates idle infrastructure:
Kinesis costs are dominated by the number of shards and PUT payload units. Starting with a single shard keeps the baseline low; scaling is linear and intentional.
Lambda is billed per request and compute duration. Choosing sensible batch sizes, memory, and timeouts lets you trade latency for cost. For example, a small batch size minimizes per-batch latency for near-immediate processing while keeping compute bursts small.
DynamoDB PAY_PER_REQUEST pricing removes the need to forecast capacity. You only pay for read and write units you actually consume. Point-in-time recovery adds a small storage cost but provides significant safety.
S3 is extremely cheap for storage, and you can optionally enable lifecycle rules to transition older data to cheaper tiers.
Glue Catalog has negligible cost for metadata storage.
Athena costs are per TB scanned. Because the raw data is organized by time and schema-defined, it is straightforward to add partitioning or switch to Parquet later to reduce scan costs substantially.
All of this means you can run a real-time analytics stack for a small team or pilot project at very low cost and scale it progressively as value is proven and requirements grow.
Operational Flow
Deploy the infrastructure with Terraform:
terraform init,terraform validate,terraform plan, andterraform apply.Confirm the SNS email subscription sent for the
stock-trend-alertstopic.Start the producer: optionally set
KINESIS_STREAM_NAME, then runpython producer_data_function.py. Records will begin flowing into Kinesis.Observe processing: the consumer Lambda archives raw JSON to S3 and writes curated items to DynamoDB. The trend Lambda listens to DynamoDB Streams and publishes alerts when it detects SMA crossovers.
Query archived data in Athena: open the Athena console, select the Glue database and table, and run SQL against your archived JSON. Results will appear in the query results bucket.
Tear down if needed: because the S3 module uses
force_destroy = true,terraform destroywill delete the buckets even if objects remain. If you just enabled force-destroy, apply that change first, then destroy.
Business Benefits
Faster insights: Real-time ingestion and processing allow your teams to detect market shifts or operational anomalies as they happen. Alerts can route directly to people or systems.
Lower total cost of ownership: There are no servers to size or patch. Costs scale with usage and can remain near zero during quiet periods.
Durable data lake: By archiving raw events to S3, you keep a complete record for backtesting, trend discovery, and machine learning. Glue plus Athena provide ad-hoc SQL without building a warehouse on day one.
Operational simplicity: The system is composed of a few highly available, fully managed services. Terraform modules make the infrastructure explicit, consistent, and repeatable across environments.
Extensibility: Swap in a real market data feed, track more symbols, compute additional indicators (RSI, Bollinger Bands, VWAP), add APIs or dashboards, or stream cleaned data to other systems. The architecture is flexible by design.
Hardening and Future Enhancements
Least-privilege IAM: Replace broad managed policies with minimal, resource-scoped permissions.
Data format and partitioning: Store archived data as Parquet and add year/month/day/hour partitions for significant Athena cost and speed gains.
Observability: Add CloudWatch alarms for Kinesis iterator age, Lambda error rates and throttles, and DynamoDB activity. Consider tracing with AWS X-Ray for end-to-end visibility.
Resilience: Configure dead-letter queues on event source mappings and make Lambda writes idempotent to handle retries safely.
Multi-environment strategy: Externalize names and ARNs into variables, use remote Terraform state (S3 backend with DynamoDB locking), and adopt a consistent tagging scheme for cost allocation.
Conclusion
This project is a concise blueprint for real-time analytics on AWS. Kinesis streams events in; Lambda transforms and stores; DynamoDB enables instantaneous lookups; S3 plus Glue make history queryable with Athena; and SNS turns analytics into action. Expressed as Terraform modules, the stack is simple to deploy, easy to understand, and inexpensive to run.
Whether you are prototyping trading signals, monitoring application events, or analyzing IoT telemetry, this architecture gives you a pragmatic, cost-efficient foundation that scales as your needs grow.
LinkedIn: linkedin.com/in/ramon-villarin
Portfolio Site: MonVillarin.com
Github Project Repo: https://github.com/kurokood/stock-market-data-analytics-pipeline